Returning to the Poker Data Warehouse, I dove into the text-parsing process after setting up a sketch of an initial database design, with the idea of polishing out the design at a later date. I recently completed the parsing of a sample hand history, and man was it more work than I expected! Fortunately I love writing text-parsing routines (perhaps from early career work in merge-purge duplicate removal), so the 750 line stored procedure was more a labor of love than a tedious chore. Getting into the dirty details of the source data made me think more about the 30,000 ft overview also.
I
created a representation of a 52 card deck of cards in the Poker DW, and I started thinking about how to evaluate 5 card poker hands (i.e., determining what a player had at the end of the hand). What I really want is to be able to evaluate the odds of making the best hand on the next card or the river, which would ultimately allow me to judge whether a player made the right decision. This result would be similar to the "% to win" stats that you see on TV.
After I created my deck of cards, I started playing around with representing a hand of 5 cards. How many possible 5 card hands are there? Easy - think of it like this. Take 1 card from the deck, there's 52 cards to choose from. Take another card, there's 51 to choose from. Keep picking until you have 5 cards in your hand, that leaves 52 * 51 * 50 * 49 * 48 = 311,875,200 possible 5 card hands.
The problem with this method is that I'm picking
permutations of 5 card hands, rather than
combinations. Let's reduce my example above to picking two cards rather than five. According to that math, there are 52 * 51 = 2,652 possible two card hands. Using the card deck created above, this query will return that count, 2652 rows:
;WITH Draw1 AS (
SELECT Card1 = CardId
FROM Dim_Deck
),
Draw2 AS (
SELECT
Card1,
Card2 = CardId
FROM Dim_Deck D2
JOIN Draw1 D1
ON D1.Card1 <> D2.CardId
)
SELECT COUNT(*) FROM Draw2Note the use of the recursive CTE to create the second draw,
Draw2. So let's say that I picked the five of clubs first, and the four of hearts second. That is one of the 2,652 possible events. But the reversal of that order is also one of the possible events (picking the four of hearts first, and the five of clubs second). But I really don't care which
order the two cards come in (the permutation), I only care about the set of cards that results.
Looking at an even simpler example of a deck of 5 cards, ace to five, how many ways are there to pick two? Here's a simple matrix:

The code above will pick everything except the diagonal that shows pairs:
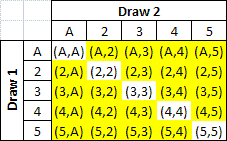
but what we really want is this:

And in order to get it, we change the "<>" operators to ">":
;WITH Draw1 AS (
SELECT Card1 = CardId
FROM Dim_Deck
),
Draw2 AS (
SELECT
Card1,
Card2 = CardId
FROM Dim_Deck D2
JOIN Draw1 D1
ON D1.Card1 > D2.CardId
)
SELECT COUNT(*) FROM Draw2
and we obtain the correct result, 1326 rows.








